Abstract MDP 1
The simplest abstract problem. A small but non-trivial random MDP with an action-dependent linear reward, easy enough that a correct estimator must recover it. It is the sanity check that the whole roster works before the harder regimes. Every estimator on the uniform estimate interface runs here. The table reports the exact recovered parameters, the recovery error, the policy distance from the truth, and the counterfactual regret.
Environment: random_mdp(num_states=8, num_actions=2, num_features=2, branching=3, discount_factor=0.9, seed=0). 300 x 50 observations, 3 replications. True theta [-0.1437, 0.7872]. Generated 2026-06-12 with econirl 0.0.4.
The data-generating process
One Garnet-style MDP is drawn from the seed and held fixed. Each state-action pair reaches a uniform random subset of \(b\) states with Dirichlet weights, mixed with a small self-loop mass \(\ell\):
The reward is linear in features of the normalized state index \(x_s = s/(S-1)\). Action \(0\) is a zeroed outside option, the identification anchor. For action \(1\),
The agent discounts at \(\beta = 0.9\) and faces i.i.d. logit taste shocks (scale \(\sigma = 1\)), so behavior solves the soft Bellman equation
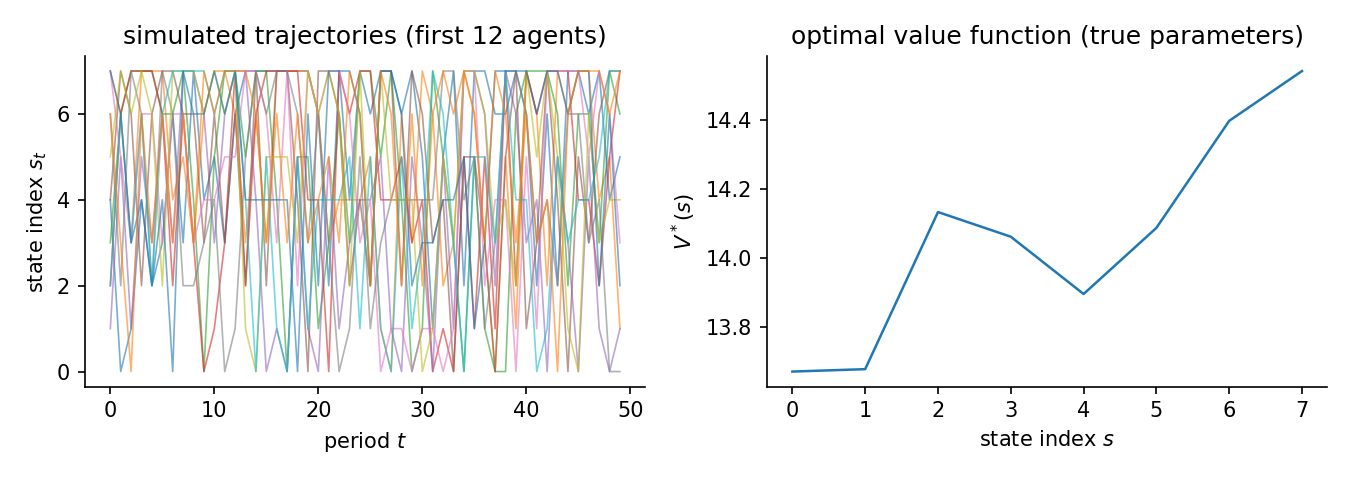
and the data are \(N\) independent agents simulated for \(T\) periods from \(\pi^*\) and the transition law. The figure shows what that produces. State paths mix across the whole space, and the optimal value function varies smoothly in the state index.
Results
Estimator |
Family |
Ran |
Conv |
Recovered params |
Param RMSE |
Policy TV |
Regret base |
Regret A |
Regret B |
Regret C |
Time (s) |
|---|---|---|---|---|---|---|---|---|---|---|---|
NFXP |
structural |
3/3 |
3/3 |
[-0.154, 0.797] |
0.0251 |
0.0025 |
0.0002 |
0.0002 |
0.0002 |
0.0000 |
4.1 |
CCP |
structural |
3/3 |
3/3 |
[-0.154, 0.797] |
0.0250 |
0.0025 |
0.0002 |
0.0002 |
0.0002 |
0.0000 |
2.1 |
MPEC |
structural |
3/3 |
3/3 |
[-0.154, 0.797] |
0.0251 |
0.0025 |
0.0002 |
0.0002 |
0.0002 |
0.0000 |
0.3 |
NNES |
structural |
3/3 |
3/3 |
[-0.154, 0.797] |
0.0251 |
0.0025 |
0.0002 |
0.0002 |
0.0002 |
0.0000 |
11.0 |
SEES |
structural |
3/3 |
1/3 |
[-0.154, 0.797] |
0.0254 |
0.0025 |
0.0002 |
0.0002 |
0.0002 |
0.0000 |
0.9 |
TD-CCP |
structural |
3/3 |
3/3 |
[-0.155, 0.794] |
0.0215 |
0.0021 |
0.0002 |
0.0002 |
0.0002 |
0.0000 |
3.1 |
UFXP |
structural |
3/3 |
3/3 |
[-0.155, 0.796] |
0.0248 |
0.0025 |
0.0002 |
0.0002 |
0.0002 |
0.0000 |
0.1 |
MCE-IRL |
behavioral |
3/3 |
0/3 |
[-0.154, 0.797] |
- |
0.0025 |
0.0002 |
0.0002 |
0.0002 |
0.0000 |
5.3 |
MaxEnt-IRL |
behavioral |
3/3 |
3/3 |
[-0.348, 0.923] |
- |
0.0101 |
0.0056 |
0.0062 |
0.0016 |
0.0000 |
13.2 |
IQ-Learn |
behavioral |
3/3 |
3/3 |
[-0.219, 0.773] |
- |
0.0370 |
0.0091 |
0.0101 |
0.0096 |
0.0000 |
1.2 |
GLADIUS |
behavioral |
3/3 |
3/3 |
[-0.380, 0.915] |
- |
0.0165 |
0.0062 |
0.0066 |
0.0044 |
0.0000 |
15.9 |
AIRL |
behavioral |
3/3 |
1/3 |
[0.147, 0.522] |
- |
0.0324 |
0.0513 |
0.0554 |
0.0297 |
0.0000 |
95.4 |
f-IRL |
behavioral |
3/3 |
3/3 |
different parameterization (16 values) |
- |
0.0091 |
0.0034 |
0.0462 |
0.0736 |
61.4508 |
22.0 |
BC |
behavioral |
3/3 |
3/3 |
different parameterization (16 values) |
- |
0.0088 |
0.0026 |
0.0423 |
0.0676 |
61.4560 |
0.2 |
Param RMSE covers the structural family only, which shares the parameterization of the true model. Policy TV is the distance between estimated and true choice probabilities, lower is better. Conv is the estimator’s own convergence flag. A cautious flag can read False while the recovered policy is accurate. Regret base is welfare lost in the observed environment. Types A, B, and C are welfare lost after a change. Type A shifts a payoff, Type B changes the transitions, Type C penalizes an action. Estimators with a recovered reward re-solve it and adapt. Those without one keep their old policy.
Configs are modest quick-run defaults, not tuned.
Reproduce
python scripts/quick_all_estimators.py --replications 3 # run + write JSON
python scripts/quick_all_estimators.py --page # regenerate this page
python scripts/quick_all_estimators.py --verify # re-derive the table from JSON
Raw facts: validation/results/quick_all_estimators.json.
Excluded from this run: MCE-IRL-NN (uses the sklearn .fit interface, not the uniform .estimate path); GAIL (known slow (~9 min/fit); not a quick run); DeepMaxEnt-IRL (known slow (~7 min/fit); not a quick run); Bayesian-IRL (known slow (~16 min/fit); not a quick run).